I/O漫谈–以 fio 命令为例
fio 命令可以方便的对Linux系统进行硬盘I/O性能方面的测试。
软件Github地址:https://github.com/axboe/fio/
1、安装及环境配置
测试环境:centos6.9(x64)
硬件配置(其中vdb和vdc是SSD):
[root@x ~]# grep -E "model name|physical id" /proc/cpuinfo |sort|uniq model name : Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz physical id : 0 [root@x ~]# free -g total used free shared buffers cached Mem: 125 27 97 12 0 15 -/+ buffers/cache: 12 113 Swap: 1 0 1 [root@CMN-SC-CTU5-190 ~]# fdisk -l|grep GB Disk /dev/vda: 107.4 GB, 107374182400 bytes Disk /dev/vdb: 751.6 GB, 751619276800 bytes Disk /dev/vdc: 751.6 GB, 751619276800 bytes Disk /dev/vdd: 5368.7 GB, 5368709120000 bytes Disk /dev/vde: 5368.7 GB, 5368709120000 bytes Disk /dev/vdf: 5368.7 GB, 5368709120000 bytes Disk /dev/vdg: 5368.7 GB, 5368709120000 bytes Disk /dev/vdh: 5368.7 GB, 5368709120000 bytes Disk /dev/vdi: 5368.7 GB, 5368709120000 bytes Disk /dev/vdj: 5368.7 GB, 5368709120000 bytes Disk /dev/vdk: 5368.7 GB, 5368709120000 bytes Disk /dev/vdl: 5368.7 GB, 5368709120000 bytes
fio3.0下载地址:https://github.com/axboe/fio/archive/refs/tags/fio-3.0.tar.gz
后面的测试用到了异步读写,所以先安装libaio:
yum -y install libaio-devel
下载并安装fio软件包:
wget https://github.com/axboe/fio/archive/refs/tags/fio-3.0.tar.gz tar -zvxf fio-3.0.tar.gz cd fio-fio-3.0/ ./configure --prefix=/usr/local/fio/ make && make install
因为fio没有写入系统环境,所以做个软链:
ln -s /usr/local/fio/bin/fio /usr/sbin/fio
2、fio命令参数解释
fio命令参数比较多,这里列举出几个常用的:
filename=/dev/emcpowerb 支持文件系统或者裸设备,-filename=/dev/sda2或-filename=/dev/sdb direct=1 测试过程绕过机器自带的buffer,使测试结果更真实 rw=randwread 测试随机读的I/O rw=randwrite 测试随机写的I/O rw=randrw 测试随机混合写和读的I/O rw=read 测试顺序读的I/O rw=write 测试顺序写的I/O rw=rw 测试顺序混合写和读的I/O bs=4k 单次io的块文件大小为4k bsrange=512-2048 同上,提定数据块的大小范围 size=5g 本次的测试文件大小为5g,以每次4k的io进行测试 numjobs=30 本次的测试线程为30,这里用了几,后面每个用-name指定的任务就开几个线程测试。所以最终线程数=任务数(几个name=jobx)* numjobs runtime=1000 测试时间为1000秒,如果不写则一直将5g文件分4k每次写完为止 ioengine=psync io引擎使用pync方式,如果要使用libaio引擎,需要yum install libaio-devel包 iodepth=16 队列的深度为16.在异步模式下,CPU不能一直无限的发命令到SSD。比如SSD执行读写如果发生了卡顿,那有可能系统会一直不停的发命令,几千个,甚至几万个,这样一方面SSD扛不住,另一方面这么多命令会很占内存,系统也要挂掉了。这样,就带来一个参数叫做队列深度。 rwmixwrite=30 在混合读写的模式下,写占30% rwmixread=30 在混合读写的模式下,读占30% group_reporting 关于显示结果的,汇总每个进程的信息 lockmem=1g 只使用1g内存进行测试 zero_buffers 用0初始化系统buffer nrfiles=8 每个进程生成文件的数量
测试中为了和实际的硬盘使用程序特性相近,使用单线程80K随机异步读写,其中写占比20%。
测试脚本:fio.sh
各个硬盘的测试结果:vdb vdc vdd vde vdf vdg vdh vdi vdj vdk vdl
结果字段的解释如下:
io=执行了多少M的IO bw=平均IO带宽 iops=IOPS runt=线程运行时间 slat=提交延迟 clat=完成延迟 lat=响应时间 bw=带宽 cpu=利用率 IO depths=io队列 IO submit=单个IO提交要提交的IO数 IO complete=Like the above submit number, but for completions instead. IO issued=The number of read/write requests issued, and how many of them were short. IO latencies=IO完延迟的分布 io=总共执行了多少size的IO aggrb=group总带宽 minb=最小.平均带宽. maxb=最大平均带宽. mint=group中线程的最短运行时间. maxt=group中线程的最长运行时间. ios=所有group总共执行的IO数. merge=总共发生的IO合并数. ticks=Number of ticks we kept the disk busy. io_queue=花费在队列上的总共时间. util=磁盘利用率
从结果可以看到一个比较显著的特点是psync模式下不论命令参数的 iodepth 设置为多少,实际测试中队列深度始终不会大于1。
测试期间服务器的 vmstat 数据(每隔2秒采集一次):vmstat
测试期间服务器的 iostat 数据(每隔2秒采集一次):iostat
关于 vmstat 的结果在之前的文章中已经有说明,iostat 的结果字段说明如下:
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge); wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。 r/s: 该设备的每秒完成的读请求数(merge合并之后的) w/s: 该设备的每秒完成的写请求数(merge合并之后的) rsec/s:每秒读取的扇区数; wsec/:每秒写入的扇区数。 rKB/s:每秒发送给该设备的总读请求数 wKB/s:每秒发送给该设备的总写请求数 avgrq-sz 平均请求扇区的大小,每个扇区一般是512byte(0.5KB),所以每次I/O的大写只要用这个指标的值乘以0.5即可 avgqu-sz 是平均请求队列的长度。毫无疑问,队列长度越短越好。 await: 每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。 svctm: 表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。 %util: 在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
3、关于硬盘队列
lsscsi -l 可以查看硬盘的队列深度queue_depths。加大硬盘队列深度就是让硬盘不断工作,减少硬盘的空闲时间。加大队列深度 –>提高利用率 –>获得IOPS和MBPS峰值 –>注意响应时间在可接受的范围内,增加队列深度的办法有很多,使用异步IO,同时发起多个IO请求,相当于队列中有多个IO请求,多线程发起同步IO请求,相当于队列中有多个IO请求。增大应用IO大小,到达底层之后,会变成多个IO请求,相当于队列中有多个IO请求 队列深度增加了。队列深度增加了,IO在队列的等待时间也会增加,导致IO响应时间变大,这需要权衡。
为何要对磁盘I/O进行并行处理呢?主要目的是提升应用程序的性能。这一点对于多物理磁盘组成的虚拟磁盘(或 LUN)显得尤为重要。如果一次提交一个I/O,虽然响应时间较短,但系统的吞吐量很小。相比较而言,一次提交多个I/O既缩短了磁头移动距离(通过电梯算法),同时也能够提升 IOPS。假如一部电梯一次只能搭乘一人,那么每个人一但乘上电梯,就能快速达到目的地(响应时间),但需要耗费较长的等待时间(队列长度)。因此一次向磁盘系统提交多个I/O能够平衡吞吐量和整体响应时间。
理论上,磁盘的IOPS取决于队列长度÷平均IO响应时间。假设队列长度为3,平均IO响应时间是10ms,则最大吞吐量是300 IOPS。
以AIX系统为例,从应用层到磁盘物理层的IO堆栈如下所示,IO按照从上至下的顺序遍历堆栈:
应用程序层:
-
文件系统层(可选)
-
LVM设备驱动层(可选)
-
SDD或SDDPCM或其他多路径驱动层(如果使用)
-
hdisk设备驱动层
-
adapter设备驱动层
-
磁盘接口层
-
磁盘子系统层
-
磁盘层
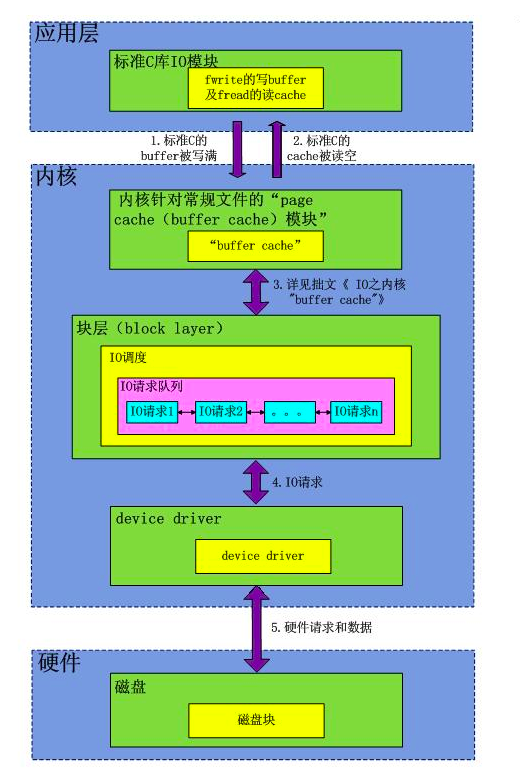
AIX在每一层堆栈都会监测IO,因此堆栈的每一层都有IO队列。通常,如果当前各层执行的IO 超过了队列长度所限制的最大数量,这些IO将暂存于等待队列中,直至获取申请资源。在文件系统层,文件系统缓存限制了各文件系统的最大可执行IO数量。 LVM设备驱动层,可执行的最大IO数量受hdisk缓存的限制。在SDD层,如果dpo设备的qdepth_enable属性设置成yes,则会建立 IO队列,但也有些版本无法设置队列。SDDPCM在将IO发送至磁盘设备驱动层之前没有进行队列处理。hdisk通过queue_depth参数设置最大响应IO数量, 而FC适配层的参数为num_cmd_elems。磁盘子系统层有IO队列,单块物理磁盘可接收多个IO请求但一次只能处理一个IO。
4、I/O 队列及调度算法
首先,不应盲目增加以上队列参数值。这样有可能造成磁盘子系统过载或在启动时引起设备配置报错。因此,仅增加hdisk 的queue_depths值并不是最好的方法,而应该同时调整可提交最大IO数量。当queue_depths和发送至磁盘子系统的IO数量同时增加 时,IO响应时间可能会增加,但同时吞吐量也得到了提升。当IO响应时间接近磁盘超时时间,则说明所提交IO超过了磁盘能够处理的界限。如果看到IO超时 并在错误日志中报出IO无法完成,说明可能有硬件问题,或需要缩短队列。
调整queue_depths的一条法则是:对于随机读写或队列未满的情况,如果IO响应时间超过15ms,就不能再增加queue_depths值。一旦IO响应时间增加,瓶颈就从磁盘和adapter队列转移至磁盘子系统。调整队列长度应依据:1)实际应用程序产生的IO请求数,2)使用测试工具以观察磁盘子系统的处理能力。其中,1)为主要依据。
IO队列有以下四种状态:
-
队列已满,IO等在hdisk或adapter驱动层
-
队列未满,IO响应时间短
-
队列未满,IO响应时间长
-
队列未满,IO提交速度快于存储处理速度并导致IO丢失
我们需要把队列调整为2或3的状态。情况3表明瓶颈不在hdisk驱动层,而很有可能在磁盘子系统自身,也有可能位于adapter驱动层或SAN。
第4种情况是应该避免的。受限于存储IO请求和数据的内存大小,所有磁盘和磁盘子系统都有IO执行数量的限制。当存储丢失IO时,主机端超时,IO将被重新提交,同时等待该IO的事件将被暂停。CPU为了处理IO多做了很多事情,这种情况应该避免。如果IO最终失败,将会导致应用程序崩溃或更严重的结果。所以必须仔细确认存储的处理极限。
合理的平均IO响应时间:
假设队列中没有IO,一次读操作将会占据0至15ms,取决于寻址时间,磁盘转速,以及数据传输时间。之后数据从存储移动至主机。有时数据位于磁盘读缓存,这种情况下IO响应时间约为1ms。对于大型磁盘系统在正常工作状态下,平均IO响应时间约为5-10ms。当随机读取小数据耗时超过15ms时,表明存储较为繁忙。
写操作通常将数据写入cache中,平均耗时不到2.5ms。但是也有例外:如果存储同步将数据镜像至远端,写操作将耗费更长时间。如果写入数据量较大(多于64KB)则数据传输时间会显著增加。没有cache的情况下,写时间的读时间差不多。
如果IO是大块顺序读写,除了传输时间较长,IO会暂存于磁盘物理层队列,IO响应时间远高于平均值。例如:应用提交50个IO(50个64KB顺序读),最初几个IO会获得较快的响应时间,而最后一个IO必须等待其他49个完成,从而耗费很长的响应时间。queue_depth此值设置过大,会导致系统出现异常。
IO调度算法:
IO调度算法存在的意义有两个:一是提高IO吞吐量,二是降低IO响应时间。然而IO吞吐量和IO响应时间往往是矛盾的,为了尽量平衡这两者,IO调度器提供了多种调度算法来适应不同的IO请求场景。
以下几个算法介绍是网上抄来的,说的很详细,作者水平很高:)
-
NOOP
该算法实现了最简单的FIFO队列,所有IO请求大致按照先来后到的顺序进行操作。之所以说"大致",原因是NOOP在FIFO的基础上还做了相邻IO请求的合并,并不是完完全全按照先进先出的规则满足IO请求。
假设有如下的io请求序列:
100,500,101,10,56,1000
NOOP将会按照如下顺序满足:
100(101),500,10,56,1000
-
CFQ
CFQ算法的全写为Completely Fair Queuing。该算法的特点是按照IO请求的地址进行排序,而不是按照先来后到的顺序来进行响应。
假设有如下的io请求序列:
100,500,101,10,56,1000
CFQ将会按照如下顺序满足:
100,101,500,1000,10,56
在传统的SAS盘上,磁盘寻道花去了绝大多数的IO响应时间。CFQ的出发点是对IO地址进行排序,以尽量少的磁盘旋转次数来满足尽可能多的IO请求。在CFQ算法下,SAS盘的吞吐量大大提高了。但是相比于NOOP的缺点是,先来的IO请求并不一定能被满足,可能会出现饿死的情况。
-
DEADLINE
DEADLINE在CFQ的基础上,解决了IO请求饿死的极端情况。除了CFQ本身具有的IO排序队列之外,DEADLINE额外分别为读IO和写IO提供了FIFO队列。读FIFO队列的最大等待时间为500ms,写FIFO队列的最大等待时间为5s。FIFO队列内的IO请求优先级要比CFQ队列中的高,而读FIFO队列的优先级又比写FIFO队列的优先级高。优先级可以表示如下:
FIFO(Read) > FIFO(Write) > CFQ
这个算法特别适合数据库这种随机读写的场景。
-
ANTICIPATORY
CFQ和DEADLINE考虑的焦点在于满足离散IO请求上。对于连续的IO请求,比如顺序读,并没有做优化。为了满足随机IO和顺序IO混合的场景,Linux还支持ANTICIPATORY调度算法。ANTICIPATORY的在DEADLINE的基础上,为每个读IO都设置了6ms的等待时间窗口。如果在这6ms内OS收到了相邻位置的读IO请求,就可以立即满足。
IO调度器算法的选择,既取决于硬件特征,也取决于应用场景。
在传统的SAS盘上,CFQ、DEADLINE、ANTICIPATORY都是不错的选择;对于专属的数据库服务器,DEADLINE的吞吐量和响应时间都表现良好。然而在新兴的固态硬盘比如SSD、Fusion IO上,最简单的NOOP反而可能是最好的算法,因为其他三个算法的优化是基于缩短寻道时间的,而固态硬盘没有所谓的寻道时间且IO响应时间非常短。
IO调度算法的查看和设置:
查看和修改IO调度器的算法非常简单。假设我们要对sda进行操作,如下所示:
cat /sys/block/sda/queue/scheduler echo 'cfq' >/sys/block/sda/queue/scheduler
查看某个硬盘的队列长度:
cat /sys/block/sda/queue/nr_requests
5、I/O BS及IOPS
参数
-
IPOS: 每秒执行的 IO 操作数量
-
BS: 每次 IO 请求的数据大小.
-
Throughput: 吞吐量
IOPS BS Throughput 关系:Throughput ~= IOPS * BS
在 BS 过小的时候, 这个公式的误差越大. 因为这个时间 IOSP 是瓶颈。当 BS 增大的时间, Throughput 一般会成为瓶颈。这个时间 Throughput 是一个变化不大的值, 所以 IOPS 与 BS 近似成反函数关系,如下:
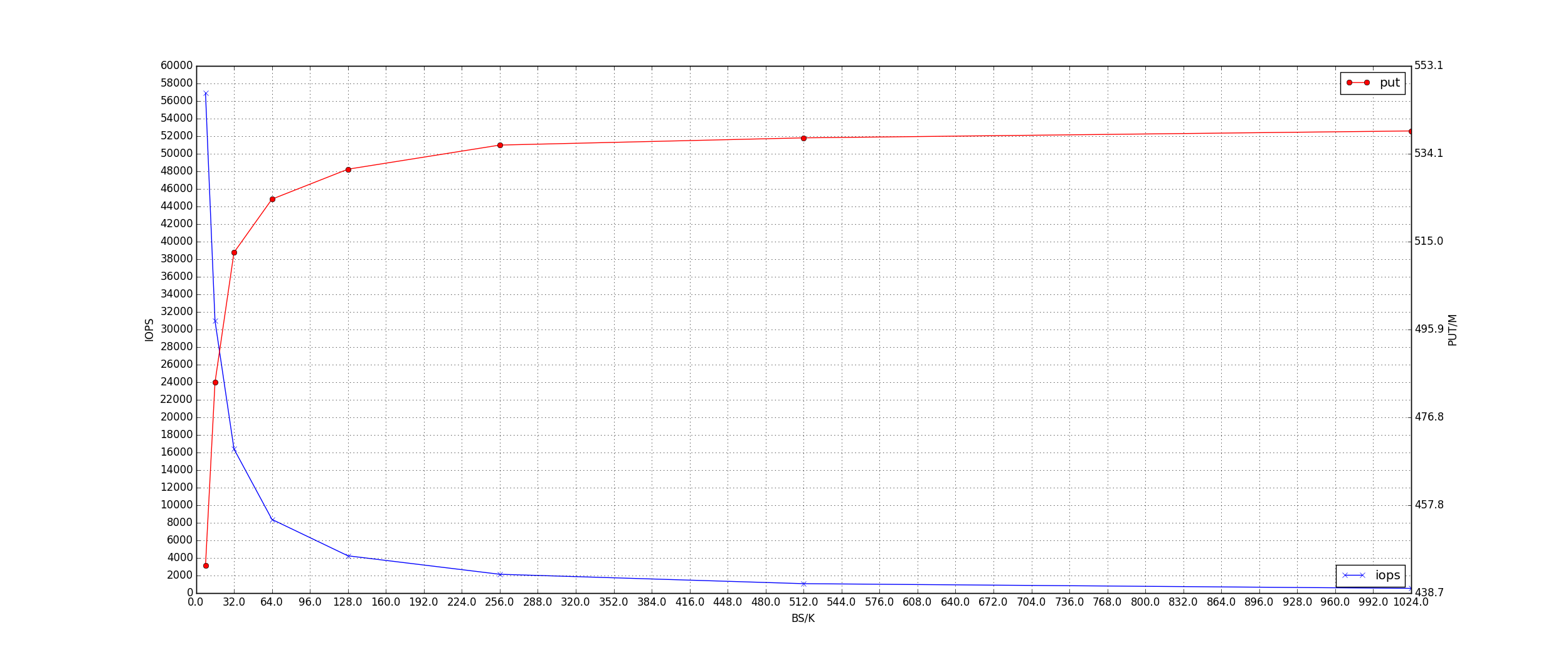
考虑我们的业务场景, 我们关心的是响应时间与平均吐出量.所以谓平均吐出量, 是我们要求对于每一个IO 的吐出量, 而不是总的吐出量.
我们希望每一个 IO 都是公平的.
IOPS 的意义
对于 CDN 网络, 命中率是根本. 不考虑内存缓存的情况下, 可以认为, 整个 CDN 网络实际上是由
磁盘进行驱动的.
IOPS 表示, 磁盘1s 可以执行的请求的数量. 换言之, 就是我们的服务可以处理的请求数.
如果所有的用户的数据都 1M 以上的, 那么不考虑 RAM, 我们的服务器的并发能力只有 500 左右.
BS 的意义
BS 是一次 IO 请求的大小.
考虑一种情况, 当用户提前中断了请求, 但是 IO 请求已经发送, 那么这一次的 IO 操作就是白费的, 因为不会
产生网络流量. 所以当 BS 越大, 这个浪费就越大.
另一个问题是阻塞, 当请求一段比较大的数据的时候, 磁盘只能专心处理这一个请求. SSD 有并行的能力, 但是这个
能力是限的. 我们的服务, 不应该一下子, 阻塞在一段数据上, 而可以把处理的时间分片给不同的请求, 从而保证每一个 IO 的公平行.
理论模型:
-
有效性
对于我们的业务而言, 有效的数据并不是从磁盘里读取的数据, 而是通过网络发送出去的数据.
只有当数据发送给了用户, 我们这一次的开销才是有价值的.
而实际上, 有很多时间, 我们完成了 IO 操作, 但是用户可能中断了, 网络请求. 这个时候我们的
IO 操作就变得没有意义了. 我们一次性请求的数据越大浪费也就越大.
-
公平性
对于所有的并发性的请求, 完全做到公平是不可能的, 虽然 SSD 可以并发处理, 但是并发有限.
对于磁盘来说, 所有的请求都是排队的, 想完全
公平地处理所有的请求, 是不可能的. 只能减小在一个请求上的阻塞的时间. 加快请求队列的处理速度.
在实际的请求中, 请求的大小是不相同的. 如果请求 1M 数据, 等待 1s, 处理完成是 1m/s.
但是如果 100k 的数据等待 1s, 处理完成的时间速度是 100k/s.
所以大的 IO 请求的存在, 会很大程序上影响其它的请求的响应.
-
速度
一个完整的文件请求的所花费的时间包括:
-
等待时间(w1)
-
处理时间(w2)
-
间隔时间(w3)
如果, 只要一次 IO 就可以完成, 那么时间开销只有(w1+w2)。w2 的开销, 理论上是固定的. 等于 Size/DSpeed。当要多次才能完成一个完整的文件请求的时候, 间隔时间就非常重要的. 这个时间与并发量有关. 当并发很高的情况下,间隔时间就会很长. 从而降底速度。
HTTP请求
对于 http 的性能的影响, 从以下几个方面进行分析:
-
首包时间
-
总下载时间
-
body 的间隔时间
以下进行测试, 设置 ATS 的不同最大分段大小,并发 2000 个请求, 总共 2000 个请求,测试文件大小 1M,硬盘型号:Intel 520 Series SSDs
首包时间
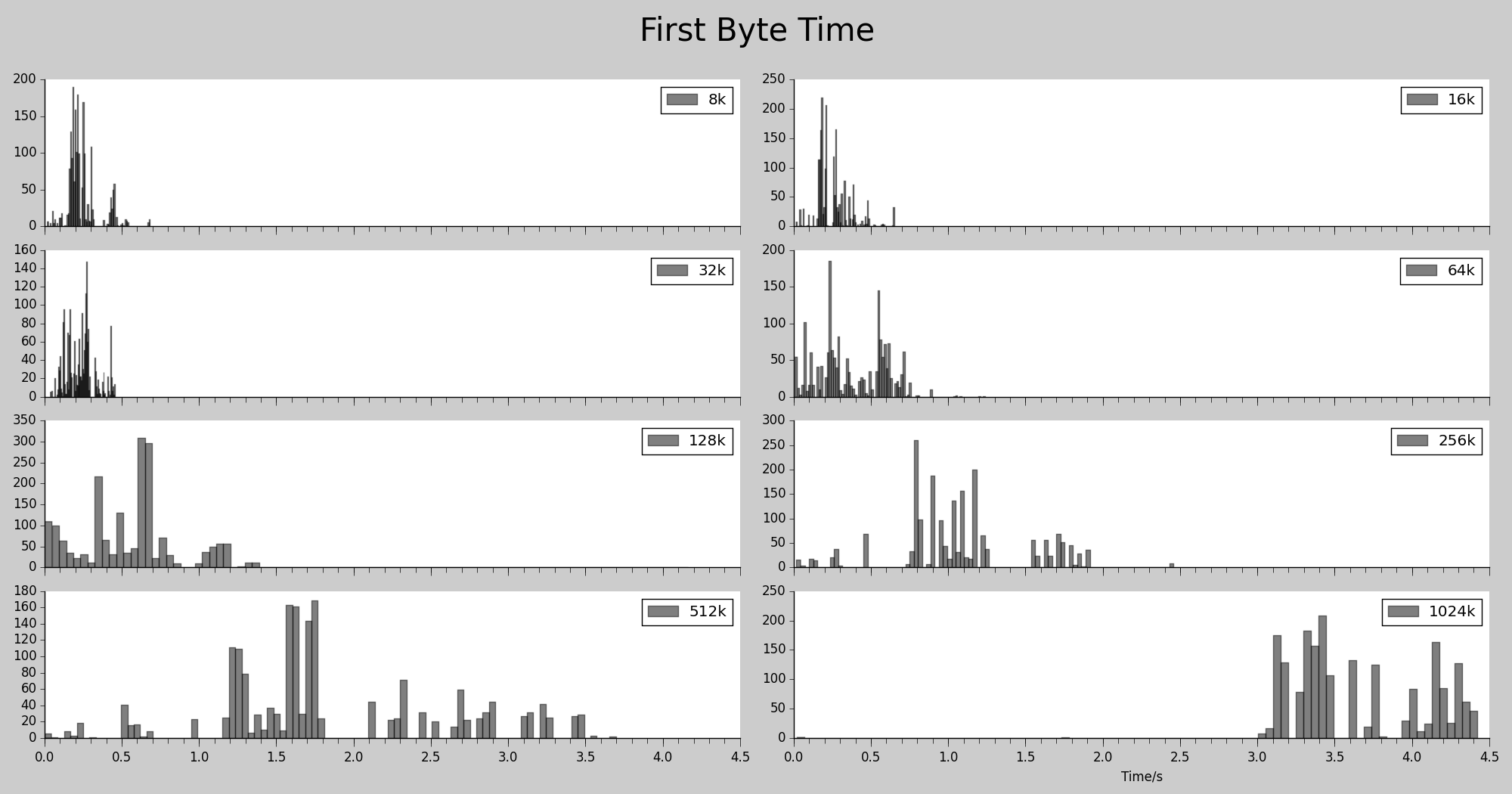
图中显示的是, 各个 BS 下对应的文件磁盘命中的情况下的, 客户端收到的首包时间.文件比较大的时候, 表现比较差, 这个符合我们的预期. 128k 以下的各个BS测试的时间比较相近,64k 的表现更好一些。
下载总时间
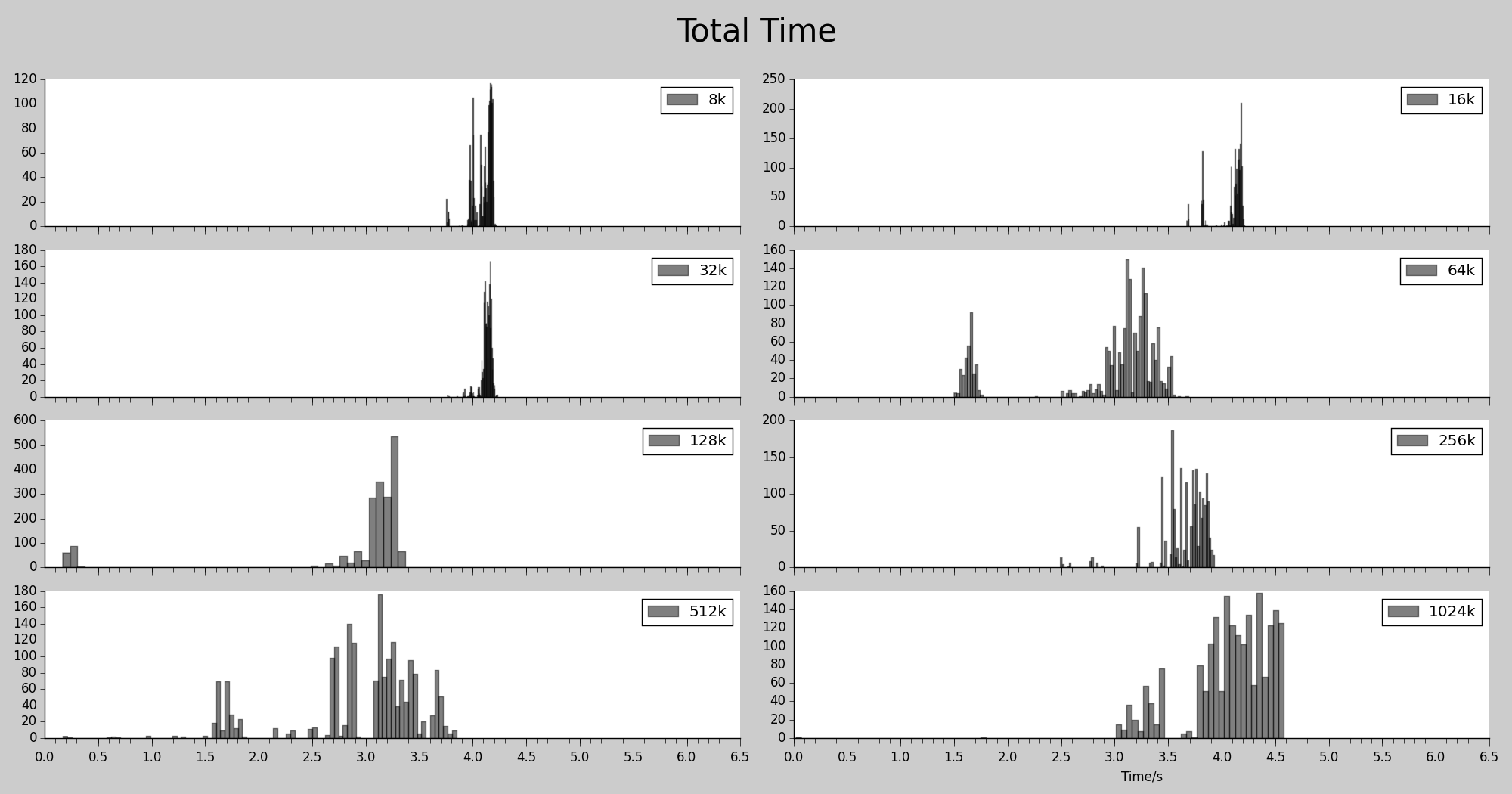
图中显示的是, 各个 BS 下对应的文件磁盘命中的情况下的, 客户端下载整个文件所用的时间。1M 的 bs 表现最差, 这一点意外. 64k 同样也是表现最好,用时最少。
最大间隔时间
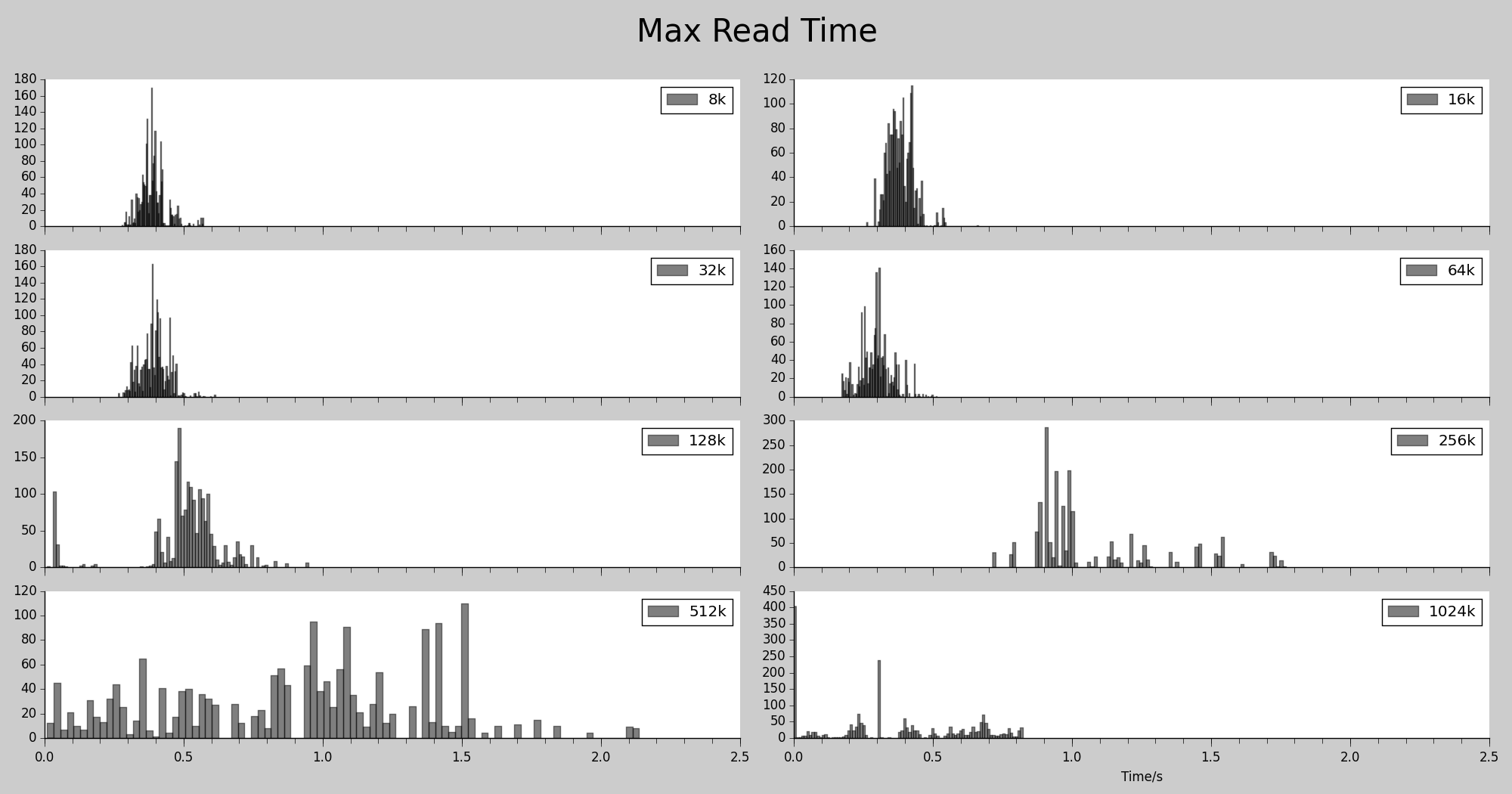
图中显示的是, 各个 BS 下对应的文件磁盘命中的情况下的, 客户端过程中两次 read socket 的最大间隔时间。同样是 64k 表现最好, 这一点是完全意外的。
proxy.config.cache.target_fragment_size:
-
介绍
这个参数用于设定 ATS 保存数据的分片大小. 一个文件的大小如果大于这个值, 文件在保存到磁盘的时候,
会分成多个 fragment, 每一个 fragment 的大小由这个参数进行控制. 当然, 如果文件小于这值, 在保存的时候 fragment
自然会缩小.
-
影响
这个参数的调整, 对于已有的缓存没有影响. 只对于新的缓存会有影响. 并且可以在运行中进行调整.
-
注意
这个 fragment 是针对于磁盘的分片的, 这里面还要包含有 HTTP 头.
-
大文件方案
大文件方案也有必要参考这个值, 但是不能直接使用, 而是要减去 HTTP 头的大小作为大文件的 slice.
proxy.config.cache.min_average_object_size
调整 target_fragment_size 之后, 这个值必须进行调整, 不然可能会引发问题. 但是这个值的调整会让缓存失效. 目前这个值是 100k, 官方的默认是 8000. 这个值还与内存的占用有关系. 8000 的情况下, 1T 的磁盘会让 ats 占用 1g 的内存.
后续
目前只测试了 2000 并发这一情况. 还有一些情况没有测试到. 但是总的方向: 降底 BS 是一定的.还有一些没有研究的方向, 还要后续进行研究。
6、补充说明 iostat 命令
重点需要关注的是下面几个指标:
-
avgrq-sz:每个 IO 的平均扇区数,即所有请求的平均大小,以扇区(512字节)为单位
-
avgqu-sz:平均意义上的请求队列长度
-
await:平均每个 I/O 花费的时间,包括在队列中等待时间以及磁盘控制器中真正处理的时间
-
svctm:每个 I/O 的服务时间。但注意上面的解释Warning! Do not trust this field any more。iostat 中关于每个 I/O 的真实处理时间不可靠
-
util:磁盘繁忙程度,单位为百分比
当系统性能下降时,我们往往需要着重关注上面列出来的 5 个参数,比如:
-
I/O 请求队列是否过长?
-
I/O size 是否过大或过小?
-
是否造成了 I/O 等待过长?
-
每个 I/O 处理时间是否过大?
-
磁盘压力是否过大?
综合分析上述指标,可以得到一定的性能分析结论,但需要注意一些陷阱。
注意陷阱
我们看到上面 iostat 的输出如下:
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sda 0.00 253.00 0.02 10.26 0.66 2081.56 405.05 0.65 62.78 6.01 62.92 4.55 4.68
svctm 为 4.55 ms,即每个 I/O 处理时间为 4.55 ms,这其实是有点偏慢了,但是 await 却高达 62.78 ms,为何?
上面可以看到总的 I/O 数为『读 I/O』+ 『写 I/O』 = 0.02 + 10.26 ≈ 11 个,假设这 11 个 I/O 是同时发起,且磁盘是顺序处理的情况,那么平均等待时间计算如下:
平均等待时间 = 单个 I/O 处理时间 * ( 1 + 2 + 3 + ...+ I/O 请求总数 - 1 ) / 请求总数 = 4.55 * ( 1 + 2 + 3 + ... + 10) / 11 = 22.75 ms
解释如下:
可以把 iostat 想像成 超市付款处,有 11 个顾客排队等待付款,只有一个收银员在服务,每个顾客处理时间为 4.55 ms,第一个顾客不需要等待,第二个顾客需要等待第一个顾客的处理时间,第三个顾客需要等待前面两位的处理时间…以此类推,所有等待时间为 单个 I/O 处理时间 * ( 1 + 2 + 3 + …+ I/O 请求总数 – 1 ).
计算得到的平均等待时间为 22.75 ms,再加上单个 I/O 处理时间 4.55 ms 得到 27.3 ms:
22.75 + 4.55 = 27.3 ms
27.3 ms可以表征 iostat 中的 await 指标,因为 await 包括了等待时间和实际处理时间。但 iostat 的 await 为 62.78 ms,为何会比 iostat 得到的 await 值小这么多?why?
27.3 ms < 62.78 ms
再次查看计算方法,步骤和原理都是正确的,但其中唯一不准确的变量就是单个 I/O 的处理时间 svctm!另外就是前提假定了磁盘是顺序处理 I/O 的。
那么是不是 svctm 不准确呢?或者磁盘并不是顺序处理 I/O 请求的呢?
丢弃 svctm
我们一直想要得到的指标是能够衡量磁盘性能的指标,也就是单个 I/O 的 service time。但是 service time 和 iostat 无关,iostat没有任何一个参数能够提供这方面的信息。人们往往对 iostat 抱有过多的期待!
Warning! Do not trust this field any more. This field will be removed in a future sysstat version.
man 手册中给出了这么一段模凌两可的警告,却没有说明原因。那么原因是什么呢?svctm 又是怎么得到的呢?
iostat 命令来自 sysstat 工具包,翻阅源码可以在 rd_stats.c 找到 svctm 的计算方法,其实 svctm 的计算依赖于其他指标:
/*
***************************************************************************
* Compute "extended" device statistics (service time, etc.).
*
* IN:
* @sdc Structure with current device statistics.
* @sdp Structure with previous device statistics.
* @itv Interval of time in 1/100th of a second.
*
* OUT:
* @xds Structure with extended statistics.
***************************************************************************
*/
void compute_ext_disk_stats(struct stats_disk *sdc, struct stats_disk *sdp,
unsigned long long itv, struct ext_disk_stats *xds)
{
double tput
= ((double) (sdc->nr_ios - sdp->nr_ios)) * 100 / itv;
xds->util = S_VALUE(sdp->tot_ticks, sdc->tot_ticks, itv);
xds->svctm = tput ? xds->util / tput : 0.0;
/*
* Kernel gives ticks already in milliseconds for all platforms
* => no need for further scaling.
*/
xds->await = (sdc->nr_ios - sdp->nr_ios) ?
((sdc->rd_ticks - sdp->rd_ticks) + (sdc->wr_ticks - sdp->wr_ticks)) /
((double) (sdc->nr_ios - sdp->nr_ios)) : 0.0;
xds->arqsz = (sdc->nr_ios - sdp->nr_ios) ?
((sdc->rd_sect - sdp->rd_sect) + (sdc->wr_sect - sdp->wr_sect)) /
((double) (sdc->nr_ios - sdp->nr_ios)) : 0.0;
}
其中重点关注:
xds->svctm = tput ? xds->util / tput : 0.0;
学过 C 语言的都知道这是一个三元运算符:
A ? B : C
表示如果 A 为真,那么表达式值为 B,否则为 C
tput 可以理解为 IOPS,即当 IOPS 非零时,svctm 等于 util / tput;否则等于 0。
tput 相当于 IOPS,下文会作解释。
上面说的 svctm 的计算依赖的值就是 util,那么 man 手册给出的警告应该废弃 svctm 的原因是不是因为 util 的计算不准确呢?
util 磁盘饱和度
上面说到应该废弃 svctm 指标,因为它并不能作为衡量磁盘性能的指标,svctm 的计算是不准确的。但从上面的计算公式可以看到,唯一的不确定的变量是 util 的值。util 是用来衡量磁盘饱和度的指标,那么 util 是怎么计算的呢?还是上面的 compute_ext_disk_stats 函数:
void compute_ext_disk_stats(struct stats_disk *sdc, struct stats_disk *sdp,
unsigned long long itv, struct ext_disk_stats *xds)
{
double tput
= ((double) (sdc->nr_ios - sdp->nr_ios)) * 100 / itv;
xds->util = S_VALUE(sdp->tot_ticks, sdc->tot_ticks, itv);
...
}
进一步阅读源码找到 S_VALUE 的定义:
#define S_VALUE(m,n,p) (((double) ((n) - (m))) / (p) * 100)
且上面的注释可以看到:
* @sdc Structure with current device statistics. * @sdp Structure with previous device statistics. * @itv Interval of time in 1/100th of a second.
最终得到 util 的计算方法为:
util = ( current_tot_ticks - previous_tot_ticks ) / 采样周期 * 100
那么 tot_ticks 是什么呢?这里需要关注 stats_disk 这个结构体,查阅源码在 rd_stats.h 文件中:
/* rd_stats.h */
/* Structure for block devices statistics */
struct stats_disk {
unsigned long long nr_ios;
unsigned long rd_sect __attribute__ ((aligned (8)));
unsigned long wr_sect __attribute__ ((aligned (8)));
unsigned int rd_ticks __attribute__ ((aligned (8)));
unsigned int wr_ticks;
unsigned int tot_ticks;
unsigned int rq_ticks;
unsigned int major;
unsigned int minor;
};
这里看不出具体每个字段是什么意义,源文件也没有作注释,接着看 rd_stats.c 文件是怎么对结构体赋值的,源文件 rd_stats.c 中:
/*
***************************************************************************
* Read block devices statistics from /proc/diskstats.
*
*/
__nr_t read_diskstats_disk(struct stats_disk *st_disk, __nr_t nr_alloc,int read_part)
{
...
if ((fp = fopen(DISKSTATS, "r")) == NULL)
return 0;
while (fgets(line, sizeof(line), fp) != NULL) {
if (sscanf(line, "%u %u %s %lu %*u %lu %u %lu %*u %lu"
" %u %*u %u %u",
&major, &minor, dev_name,
&rd_ios, &rd_sec, &rd_ticks, &wr_ios, &wr_sec, &wr_ticks,
&tot_ticks, &rq_ticks) == 11) { ... }
...
}
核心代码如上,具体来讲,iostat 的使用其实是依赖于 /proc/diskstats 文件,读取 /proc/diskstats 值,然后做进一步的分析处理。这里额外介绍下 /proc/diskstats 文件:
[root@localhost ~]# cat /proc/diskstats 1 0 ram0 0 0 0 0 0 0 0 0 0 0 0 1 1 ram1 0 0 0 0 0 0 0 0 0 0 0 1 2 ram2 0 0 0 0 0 0 0 0 0 0 0 1 3 ram3 0 0 0 0 0 0 0 0 0 0 0 1 4 ram4 0 0 0 0 0 0 0 0 0 0 0 1 5 ram5 0 0 0 0 0 0 0 0 0 0 0 1 6 ram6 0 0 0 0 0 0 0 0 0 0 0 1 7 ram7 0 0 0 0 0 0 0 0 0 0 0 1 8 ram8 0 0 0 0 0 0 0 0 0 0 0 8 0 sda 82044583 3148 10966722840 222442157 24658460 2499170 2700969385 105371088 0 57897509 328196252 8 1 sda1 4144 0 339790 2859 93359 82770 4180584 671453 0 534023 674311 8 2 sda2 487 0 4114 28 0 0 0 0 0 28 28 8 3 sda3 8450 0 206387 3489 598140 1719768 413807296 6739177 0 1204240 6742537 8 4 sda4 82031488 3148 10966172437 222435779 23966958 696632 2282981505 97960444 0 57538914 321035535 8 16 sdb 6696805 672 1028622736 99268437 3479149 1095853 385460280 4357778 0 80933531 103624000 8 32 sdc 6535697 706 1003357408 101660311 3409287 1048913 370227528 4329287 0 82570947 105987603 8 48 sdd 6555170 652 1005848496 98046714 3392381 1044610 369149464 4407316 0 80348361 102451899 8 64 sde 6532011 671 1002703024 134576408 3406505 1054721 372497720 5792380 0 103162428 140366630
每个字段的意义解释如下:
The /proc/diskstats file displays the I/O statistics of block devices. Each line contains the following 14 fields: 1 - major number 2 - minor mumber 3 - device name 4 - reads completed successfully 5 - reads merged 6 - sectors read 7 - time spent reading (ms) 8 - writes completed 9 - writes merged 10 - sectors written 11 - time spent writing (ms) 12 - I/Os currently in progress 13 - time spent doing I/Os (ms) 14 - weighted time spent doing I/Os (ms)
这里英文的解释可能没有很明白很清楚,尤其是第 7 、11、13 个字段的解释,我们再用中文解释一下:
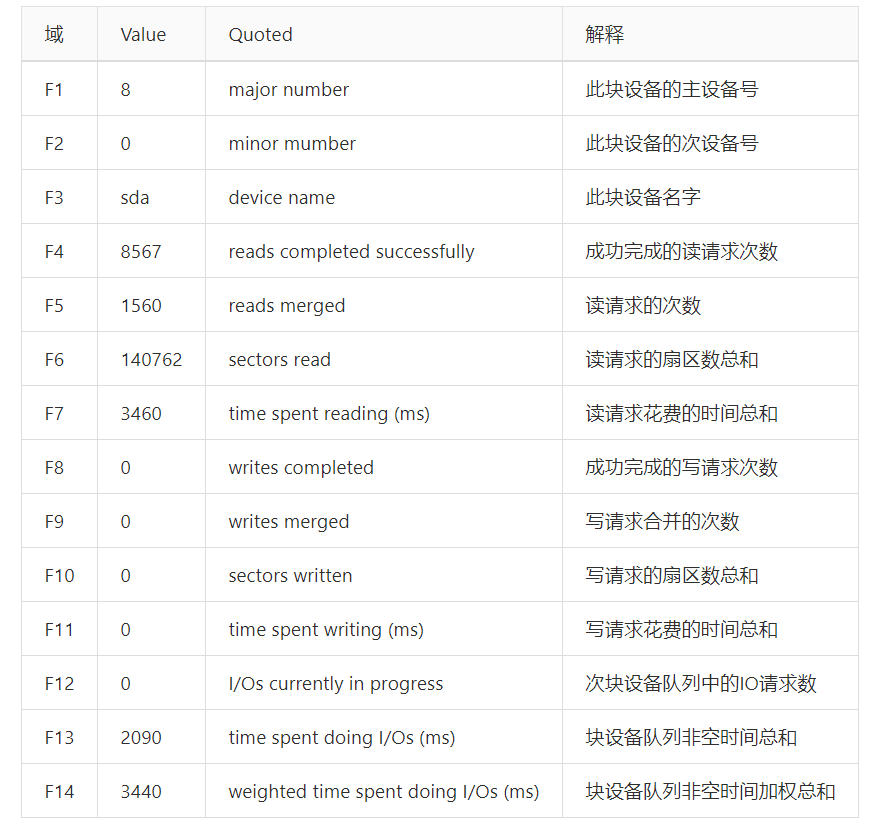
这里需要特别对第 7、11、13 个字段做一点解释,第 7 个字段表示所有读请求的花费时间总和,这里把每个读 I/O 请求都计算在内;同理是第 11 个字段;那么为什么还有第 13 个字段呢?第 13 个字段不关心有多少 I/O 在处理,它只关心设备是否在做 I/O 操作,所以真实情况是第 7 个字段加上第 11 个字段的值会比第 13 个字段的值更大一点。
回到 rd_stats.c 源码中,stats_disk 结构体是如何赋值的呢?
... while (fgets(line, sizeof(line), fp) != NULL) ... sscanf(line, "%u %u %s %lu %*u %lu %u %lu %*u %lu" " %u %*u %u %u", &major, &minor, dev_name, &rd_ios, &rd_sec, &rd_ticks, &wr_ios, &wr_sec, &wr_ticks, &tot_ticks, &rq_ticks) == 11) ...
使用 fgets 函数获得 /proc/diskstats 文件中的一行数据,然后使用 sscanf 函数格式化字符串到结构体 stats_disk 的不同成员变量中。仔细看代码,格式符号有 14 个,但接收字符串的变量只有 11 个,这里要注意的是 sscanf 的使用:
sscanf 中 * 表示读入的数据将被舍弃。带有*的格式指令不对应可变参数列表中的任何数据。
这么一来,我们要寻找的 tot_ticks 就是第 13 个字段,也就是表示:
13 - time spent doing I/Os (ms),即 花费在 I/O 上的时间
我们再回到 util 的计算:
util = ( current_tot_ticks - previous_tot_ticks ) / 采样周期 * 100
util 的计算方法是: 统计一个周期内磁盘有多少自然时间(ms) 是用来做 I/O 的,得出百分比,代表磁盘饱和度。
上文对于 svctm 的计算提到 tput 这个变量代表 IOPS,这里额外做一点解释:
/*rd_stats.c 中 read_diskstats_disk 函数内 */ /* 读 I/O + 写 I/O 数量 */ st_disk_i->nr_ios = (unsigned long long) rd_ios + (unsigned long long) wr_ios; ... /* rd_stats.c 中 compute_ext_disk_stats 函数内 */ /* 当前读写 I/O 数量 - 上一次采样时的读写 I/O 数量 */ double tput = ((double) (sdc->nr_ios - sdp->nr_ios)) * 100 / itv;
经过对 /proc/diskstats 各个字段的分析,不难得出,stats_disk 结构体中的成员变量 nr_ios 代表读写 I/O 成功完成的数量,也就是 IOPS。
再回过来,那么 util 的计算是准确的吗?tot_ticks 的计算是准确的吗?
经过上面的分析,tot_ticks 其实表示的是 /proc/diskstats 文件中第 13 个字段,表示磁盘处理 I/O 操作的自然时间,不考虑并行性。那么由此得到的 util 就失去了最原本的意义。
举个简单的例子,假设磁盘处理单个 I/O 的能力为 0.01ms,依次有 200 个请求提交,需要 2s 处理完所有的请求,如果采样周期为 1s,在 1s 的采样周期里 util 就达到了 100%;但是如果这 200 个请求分批次的并发提交,比如每次并发提交 2 个请求,即每次同时过来 2 个请求,那么需要 1s 即可完成所有请求,采样周期为 1s,util 也是 100%。
两种场景下 util 均是 100%,那一种磁盘压力更大?当然是第二种,但仅仅通过 util 并不能得出这个结论。
再回到 svctm 的计算:
double tput = ((double) (sdc->nr_ios - sdp->nr_ios)) * 100 / itv; xds->util = S_VALUE(sdp->tot_ticks, sdc->tot_ticks, itv); xds->svctm = tput ? xds->util / tput : 0.0;
转换上述两个式子可以得到:
svctm = ( current_tot_ticks - previous_tot_ticks ) / (current_ios - previous_ios ) = 采样周期内设备进行 I/O 的自然时间 / 采样周期内读写 I/O 次数
故通过此表达式计算得到的 svctm 其实并能准确衡量单个 I/O 的处理能力。如果磁盘没有并行处理的能力,那么采样周期内读写 I/O 次数必然减少,相应的,svctm 的计算就会偏大。
那回到开头提出的疑问,假定顺序请求情况下得到的平均等待时间 27.3ms 小于 iostat 看到的 await 62.78ms:
27.3 ms < 62.78 ms
现在可以解释了:27.3 ms 的计算其实使用了偏小的 svctm 值,故得到的平均等待时间较 62.78ms 小很多。
iostat 辩证看待
分析到这里,原理已经很明白了,util 并不能衡量磁盘的饱和度,svctm 的值失去了意义。期望通过这两个指标获得一个磁盘性能的衡量恐怕不行了!
但平常的分析,我们可以参考 iostat 的输出,再结合其他的一些工具,进行多方面多方位的性能分析,才能得到比较接近真理的结论!
延伸
上文分析了 iostat 容易引起误解的几个指标,在使用 iostat 时我们需要辩证的看待 iostat 的结果。
但我们往往更希望获得一个能够衡量磁盘性能的指标,iostat 可能帮不上太多忙了,这时可能需要借助其他的工具了,比如 blktrace 这个工具,这才是分析 I/O 的利器!
相关链接:
Linux IO Scheduler(Linux IO 调度器)